Under the null hypothesis, the proportion of individuals in the population that have
the characteristic is ![]() .
.
Under the assumptions that
![]() and
and
![]() , the
population standard deviation is:
, the
population standard deviation is:
and the data are approximately distributed normally with mean
With this assumption, if the null hypothesis is true, the sample proportion
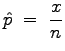
will be approximately normally distributed with the following parameters:
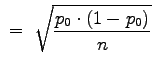
The strategy for testing the hypothesis is to consider ![]() to be a single observation
from this distribution, standardize it based on the assumption that its mean is
to be a single observation
from this distribution, standardize it based on the assumption that its mean is ![]() and
its standard deviation is
and
its standard deviation is
![]() , and base our decision to accept or reject the null hypothesis on where the standardized value or
, and base our decision to accept or reject the null hypothesis on where the standardized value or ![]() -score falls on the standard normal bell curve.
-score falls on the standard normal bell curve.
We calculate the standardized or ![]() -score for the sample proportion
-score for the sample proportion ![]() as:
as:
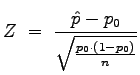
(This value is in cell B13)
The exact decision rule to accept or reject the null hypothesis depends on whether we want:
See the sections below for details on these three cases.